

Introducing InQuanto v4.0
The latest version of our advanced quantum computational chemistry platform
Quantinuum is excited to announce the release of InQuanto™ v4.0, the latest version of our advanced quantum computational chemistry software. This update introduces new features and significant performance improvements, designed to help both industry and academic researchers accelerate their computational chemistry work.
If you're new to InQuanto or want to learn more about how to use it, we encourage you to explore our documentation.
InQuanto v4.0 is being released alongside Quantinuum Nexus, our cloud-based platform for quantum software. Users with Nexus access can leverage the `inquanto-nexus` extension to, for example, take advantage of multiple available backends and seamless cloud storage.
In addition, InQuanto v4.0 introduces enhancements that allow users to run larger chemical simulations on quantum computers. Systems can be easily imported from classical codes using the widely supported FCIDUMP file format. These fermionic representations are then efficiently mapped to qubit representations, benefiting from performance improvements in InQuanto operators. For systems too large for quantum hardware experiments, users can now utilize the new `inquanto-cutensornet` extension to run simulations via tensor networks.
These updates enable users to compile and execute larger quantum circuits with greater ease, while accessing powerful compute resources through Nexus.
Quantinuum Nexus
InQuanto v4.0 is fully integrated with Quantinuum Nexus via the `inquanto-nexus` extension. This integration allows users to easily run experiments across a range of quantum backends, from simulators to hardware, and access results stored in Nexus cloud storage.
Results can be annotated for better searchability and seamlessly shared with others. Nexus also offers the Nexus Lab, which provides a preconfigured Jupyter environment for compiling circuits and executing jobs. The Lab is set up with InQuanto v4.0 and a full suite of related software, enabling users to get started quickly.
Enhanced Operator Performance
The `inquanto.mappings` submodule has received a significant performance enhancement in InQuanto v4.0. By integrating a set of operator classes written in C++, the team has increased the performance of the module past that of other open-source packages’ equivalent methods.
Like any other Python package, InQuanto can benefit from delegating tasks with high computational overhead to compiled languages such as C++. This prescription has been applied to the qubit encoding functions of the `inquanto.mappings` submodule, in which fermionic operators are mapped to their qubit operator equivalents. One such qubit encoding scheme is the Jordan-Wigner (JW) transformation. With respect to JW encoding as a benchmarking task, the integration of C++ operator classes in InQuanto v4.0 has yielded an execution time speed-up of two and a half times that of open-source competitors (Figure 1).

Figure 1. Performance comparison of Jordan Wigner (JW) operator mappings for LiH molecule in several basis sets of increasing size.
This is a substantial increase in performance that all users will benefit from. InQuanto users will still interact with the familiar Python classes such as `FermionOperator` and `QubitOperator` in v4.0. However, when the `mappings` module is called, the Python operator objects are converted to C++ equivalents and vice versa before and after the qubit encoding procedure (Figure 2). With future total integration of C++ operator classes, we can remove the conversion step and push the performance of the `mappings` module further. Tests, once again using the JW mappings scheme, show a 40 times execution time speed-up as compared to open-source competitors (Figure 1).

Figure 2. Representation of the conversion step from Python objects to C++ objects in the qubit encoding processes handled by the `inquanto.mappings` submodule in InQuanto v4.0.
Efficient classical pre-processing implementations such as this are a crucial step on the path to quantum advantage. As the number of physical qubits available on quantum computers increases, so will the size and complexity of the physical systems that can be simulated. To support this hardware upscaling, computational bottlenecks including those associated with the classical manipulation of operator objects must be alleviated. Aside from keeping pace with hardware advancements, it is important to enlarge the tractable system size in situations that do not involve quantum circuit execution, such as tensor network circuit simulation and resource estimation.
Leveraging Tensor Networks
Users with access to GPU capabilities can now take advantage of tensor networks to accelerate simulations in InQuanto v4.0. This is made possible by the `inquanto-cutensornet` extension, which interfaces InQuanto with the NVIDIA® cuTensorNet library. The `inquanto-cutensornet` extension leverages the `pytket-cutensornet` library, which facilitates the conversion of `pytket` circuits into tensor networks to be evaluated using the NVIDIA® cuTensorNet library. This extension increases the size limit of circuits that can be simulated for chemistry applications. Future work will seek to integrate this functionality with our Nexus platform, allowing InQuanto users to employ the extension without requiring access to their own local GPU resources.
Here we demonstrate the use of the `CuTensorNetProtocol` passed to a VQE experiment. For the sake of brevity, we use the `get_system` method of `inquanto.express` to swiftly define the system, in this case H2 using the STO-3G basis-set.
from inquanto.algorithms import AlgorithmVQE
from inquanto.ansatzes import FermionSpaceAnsatzUCCD
from inquanto.computables import ExpectationValue, ExpectationValueDerivative
from inquanto.express import get_system
from inquanto.mappings import QubitMappingJordanWigner
from inquanto.minimizers import MinimizerScipy
from inquanto.extensions.cutensornet import CuTensorNetProtocol
fermion_hamiltonian, space, state = get_system("h2_sto3g.h5")
qubit_hamiltonian = fermion_hamiltonian.qubit_encode()
ansatz = FermionSpaceAnsatzUCCD(space, state, QubitMappingJordanWigner())
expectation_value = ExpectationValue(ansatz, qubit_hamiltonian)
gradient_expression = ExpectationValueDerivative(
ansatz, qubit_hamiltonian, ansatz.free_symbols_ordered()
)
protocol_tn = CuTensorNetProtocol()
vqe_tn = (
AlgorithmVQE(
objective_expression=expectation_value,
gradient_expression=gradient_expression,
minimizer=MinimizerScipy(),
initial_parameters=ansatz.state_symbols.construct_zeros(),
)
.build(protocol_objective=protocol_tn, protocol_gradient=protocol_tn)
.run()
)
print(vqe_tn.generate_report()["final_value"])
# -1.136846575472054
The inherently modular design of InQuanto allows for the seamless integration of new extensions and functionality. For instance, a user can simply modify existing code using `SparseStatevectorProtocol` to enable GPU acceleration through `inquanto-cutensornet`. It is worth noting that the extension is also compatible with shot-based simulation via the `CuTensorNetShotsBackend` provided by `pytket-cutensornet`.
“Hybrid quantum-classical supercomputing is accelerating quantum computational chemistry research,” said Tim Costa, Senior Director at NVIDIA®. “With Quantinuum’s InQuanto v4.0 platform and NVIDIA’s cuQuantum SDK, InQuanto users now have access to unique tensor-network-based methods, enabling large-scale and high-precision quantum chemistry simulations.”
Classical Code Interface
As demonstrated by our `inquanto-pyscf` extension, we want InQuanto to easily interface with classical codes. In InQuanto v4.0, we have clarified integration with other classical codes such as Gaussian and Psi4. All that is required is an FCIDUMP file, which is a common output file for classical codes. An FCIDUMP file encodes all the one and two electron integrals required to set up a CI Hamiltonian. Users can bring their system from classical codes by passing an FCIDUMP file to the `FCIDumpRestricted` class and calling the `to_ChemistryRestrictedIntegralOperator` method or its unrestricted counterpart, depending on how they wish to treat spin. The resulting InQuanto operator object can be used within their workflow as they usually would.
Exposing TKET Compilation
Users can experiment with TKET’s latest circuit compilation tools in a straightforward manner with InQuanto v4.0. Circuit compilation now only occurs within the `inquanto.protocols` module. This allows users to define which optimization passes to run before and/or after the backend specific defaults, all in one line of code. Circuit compilation is a crucial step in all InQuanto workflows. As such, this structural change allows us to cleanly integrate new functionality through extensions such as `inquanto-nexus` and `inquanto-cutensornet`. Looking forward, beyond InQuanto v4.0, this change is a positive step towards bringing quantum error correction to InQuanto.
Conclusion
InQuanto v4.0 pushes the size of the chemical systems that a user can simulate on quantum computers. Users can import larger, carefully constructed systems from classical codes and encode them to optimized quantum circuits. They can then evaluate these circuits on quantum backends with `inquanto-nexus` or execute them as tensor networks using `inquanto-cutensornet`. We look forward to seeing how our users leverage InQuanto v4.0 to demonstrate the increasing power of quantum computational chemistry. If you are curious about InQuanto and want to read further, our initial release blogpost is very informative or visit the InQuanto website.
How to Access InQuanto
If you are interested in trying InQuanto, please request access or a demo at inquanto@quantinuum.com
About Quantinuum
Quantinuum, the world’s largest integrated quantum company, pioneers powerful quantum computers and advanced software solutions. Quantinuum’s technology drives breakthroughs in materials discovery, cybersecurity, and next-gen quantum AI. With over 500 employees, including 370+ scientists and engineers, Quantinuum leads the quantum computing revolution across continents.
Quantinuum is pleased to announce that applications are now open for the Quantinuum SG Grand Challenge 2026, a global innovation challenge designed to bring together researchers, developers, scientists and innovators to explore practical applications of quantum computing.
Organized by Quantinuum and supported by Singapore's National Quantum Office and Aqora, the three-month program aims to foster collaboration across academia, industry and the quantum developer community while supporting the continued growth of Singapore's quantum ecosystem.
A Platform for Quantum Computing Innovation
Participants will work in teams to develop solutions across a range of challenge areas, including chemistry and molecular simulation, optimization, AI for quantum systems, quantum error correction, condensed matter and materials science, and open innovation. Throughout the program, participants will have access to mentoring, technical enablement and Quantinuum quantum computing resources.
Singapore Grand Finale
Selected finalist teams will be invited to present their work at the Grand Finale hosted in Singapore before representatives from academia, and industry. The event will celebrate innovative applications of quantum computing while providing an opportunity for participants to engage with Singapore's growing quantum community.
Join the Challenge
The Quantinuum SG Grand Challenge welcomes participants from around the world. Whether you are an experienced quantum researcher or beginning your quantum computing journey, the program offers an opportunity to collaborate, learn and contribute to the development of practical quantum applications.
Applications are now open. Spaces are limited and subject to review and approval.
- Researchers from Quantinuum, Caltech, the University of Chicago, and Harvard created a rare topologically ordered state of matter on Quantinuum's System Model H2 and used it to perform protected universal quantum gates with non-Abelian anyons.
- The work explores an alternative approach to fault tolerance by using topological properties to protect quantum information. This could reduce the need for magic state distillation, which can (in some circumstances) be resource-intensive.
- Quantinuum continues to show leadership in fault tolerance, with successful demonstrations spanning world record error rates to exotic approaches like topological computing
Quantum computing is all about putting the exotic properties of physics to work. Qubits can exist in two states at once, like the famous cat that is both alive and dead. Qubits can also be entangled, where the state of one will instantaneously affect the state of another - even when they have no way to “talk” to each other. Qubits can even be teleported, moving a quantum state from one place to another without physically moving it through space.
These features give quantum computing its power. But the ‘spooky’ nature of quantum computing doesn’t stop there: our quantum computers are potent enough to make exotic states of matter out of our qubits, and to perform calculations that would warp the mind of more traditional thinkers.
A new approach
In a recent paper published in Nature, researchers at Quantinuum teamed up with Caltech, the University of Chicago, and Harvard to create a rare ‘topologically ordered’ state of matter from our qubits.
When the qubits become ‘topologically ordered’, they become more than individual particles, now ‘related’ to each other in a specific way. This is like how hydrogen and oxygen act as individual gas particles alone, but you can put them together in a certain way so that they become water, a liquid, and an entirely different creature.
When the qubits become topologically ordered, the quantum information that they carried individually gets spread out over the whole system, which acts as a sort of protection from noise. This is like how a net makes a stronger barrier than a bunch of un-knotted ropes.
Once the researchers had topologically ordered qubits, they used the exotic particles that resulted (called non-Abelian anyons) to compute, performing error-protected gates and measurements.
To perform gates, the researchers 'braided' the anyons, which is like changing the shape of the “net”. This is something like the children’s game ‘cats cradle’. Through a sequence of changes to the “net”, the quantum computer can perform full calculations, one day helping scientists to understand the secrets hidden in the world around us.
Why go to such trouble? Well, for the love of discovery of course - but the team had an additional, specific motivation. One of the biggest challenges in building practical quantum computers is protecting them from errors while still being able to perform every operation needed for computation (this is referred to as universality).
This work takes a fresh approach to this challenge. Unlike traditional quantum error correction, the special properties of topological matter enable a universal set of fault tolerant gates without relying on expensive magic state distillation.
Why this matters
Quantum error correction is essential for large-scale quantum computing. While it protects fragile quantum information from noise by turning delicate physical qubits into robust logical qubits, it also introduces a significant constraint: not every quantum gate can be performed directly on logical qubits.
For decades, the standard solution has been to supplement error-corrected operations with magic states. These specially prepared quantum resources enable universal computation but can come at a steep cost - in many estimates of future fault-tolerant quantum computers, magic state preparation dominates both the physical qubit count and the runtime of useful algorithms.
Reducing this overhead has therefore become an important goal in quantum computing. This new approach may significantly reduce the cost by enabling the ‘topological preparation’ of magic states, eliding expensive protocols like distillation. If universal computation can be performed without large-scale magic state distillation, quantum computers could require significantly fewer physical qubits and spend much less time generating computational resources before running useful algorithms.
We will never stop exploring
While there is still considerable work ahead to understand the practical implementation and scalability of these ideas, this result expands the landscape of what's possible in quantum fault tolerance.
Of course, this impressive demonstration describes just one approach we are taking to fault tolerance at scale. We will continue to push forward with topological computing alongside more traditional approaches to quantum error correction, as well as exploring everything we can imagine in between. We are looking at a number of ways to reduce the resource cost of magic states in particular, and are making strides in multiple dimensions. With machines that are both flexible and accurate enough to do it all, who can resist?
- Quantinuum continues its progress toward fault-tolerant quantum computing, with a series of peer-reviewed breakthroughs in fault-tolerant operations.
- Our progress is not only scientific; it is commercial. By improving logical-qubit reliability and encoding efficiency, Quantinuum is reducing the resource overhead required to scale its quantum computers toward commercially useful workloads.
- These results were achieved on commercial Quantinuum hardware, reinforcing that our architecture is not just setting new standards, but building a practical foundation for customers, partners, and researchers preparing for the fault-tolerant era.
Fault-tolerant quantum computing is the threshold the industry must cross before quantum computers can solve the hardest, highest-value problems with confidence. To be commercially useful at scale, the question is not simply who can build more qubits. It is who can build reliable, efficient, scalable systems that reduce technical risk and accelerate the path to commercial usefulness.
Quantinuum is progressing on that path.
Last year, in partnership with Microsoft, we published a breakthrough in logical computing, demonstrating logical qubits that outperformed their physical counterparts by a factor of 800. We are proud to announce that this work is now being published in Nature, one of the most highly regarded scientific journals in the world.
This work highlights our leading fidelities, as shown in Table 1:
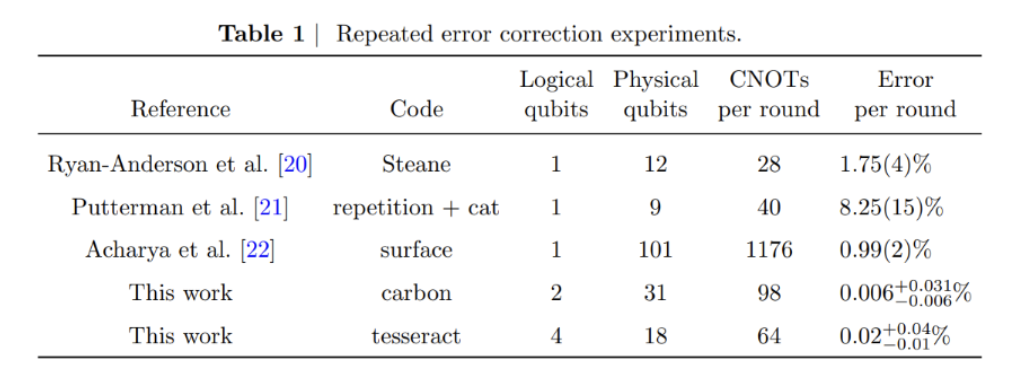
Since then, we’ve accelerated our efforts to reach large-scale fault tolerance and advanced what we believe to be the core building blocks of fault-tolerant quantum computing, from logical-qubit teleportation and multiple error-correction breakthroughs to one of the first meaningful computations using logical qubits. Importantly, these results were achieved on commercial Quantinuum hardware, demonstrating not just scientific progress, but a practical and efficient path toward scalable, customer-ready fault tolerance.
A Recap of Our Recent Technical Progress
Since the work with Microsoft, we achieved a milestone years ahead of schedule, demonstrating high-fidelity teleportation of a logical qubit, which was published in Science, one of the world’s most prestigious journals. Later, we beat our own record in this crucial fault tolerance milestone, thanks to continued improvements to our System Model H2’s fidelity.
Then, a series of results demonstrating more error-correcting milestones (and codes):
- Better than physical results in a high-rate non-local code,
- First-ever demonstration of a single-shot error correcting code (which significantly reduces resource requirements) in 4 dimensions
- Extending qubit lifetimes by 10x with a concatenated code
- Observed fault-tolerance thresholds with concatenated codes
- High fidelity magic states and a fully fault tolerant universal gate set in two different papers
Recently, we topped ourselves yet again by performing one of the first meaningful computations with logical qubits – exploring key questions in materials and magnetism, using logical qubits with better error rates than their physical counterparts. This result also includes a leading “encoding rate” squeezing 48 logical qubits out of just 98 physical qubits, emphasizing how our architecture helps to support large scale fault tolerance without enormous resource costs.
It is worth noting that all these results were achieved on our commercial hardware, not on one-off laboratory test-stands – reflecting the performance that we are able to deliver to our customers.
We also did crucial theoretical work, exploring new options for error correction that can reduce resource requirements, time to solution, and shorten the timeline to large scale fault tolerance.
Commercial Implications and the Road Ahead
We believe the commercial implication is clear: Quantinuum is reducing the uncertainty around the path to fault-tolerant quantum computing. Our architecture, hardware fidelity, full-stack control, and error-correction progress are converging into a practical roadmap for systems that can support valuable scientific and commercial workloads.
For those evaluating when quantum computing will become strategically relevant, we believe the signal is also increasingly clear: the fault-tolerant era is no longer a distant concept. It is becoming an engineering reality, and Quantinuum is leading the way.