

Quantinuum Launches the Most Benchmarked Quantum Computer in the World and Publishes All the Data
New H2-1 shows strong performance across 15 benchmarks while expanding to 32 qubits and reaching a new Quantum Volume record of 65,536
Quantinuum’s new H2-1 quantum computer proves that trapped-ion architecture, which is well-known for achieving outstanding qubit quality and gate fidelity, is also built for scale – and Quantinuum’s benchmarking team has the data to prove it.
The bottom line: the new System Model H2 surpasses the H1 in complexity and qubit capacity while maintaining all the capabilities and fidelities of the previous generation – an astounding accomplishment when developing successive generations of quantum systems.
The newest entry in the H-Series is starting off with 32 qubits whereas H1 started with 10. H1 underwent several upgrades, ultimately reaching a 20-qubit capacity, and H2 is poised to pick up the torch and run with it. Staying true to the ultimate goal of increasing performance, H2 does not simply increase the qubit count but has already achieved a higher Quantum Volume than any other quantum computer ever built: 216 or 65,536.
Most importantly for the growing number of industrials and academic research institutions using the H-Series, benchmarking data shows that none of these hardware changes reduced the high-performance levels achieved by the System Model H1. That’s a key challenge in scaling quantum computers – preserving performance while adding qubits. The error rate on the fully connected circuits is comparable to the H1, even with a significant increase in qubits. Indeed, H2 exceeds H1 in multiple performance metrics: single-qubit gate error, two-qubit gate error, measurement cross talk and SPAM.
Key to the engineering advances made in the second-generation H-Series quantum computer are reductions in the physical resources required per qubit. To get the most out of the quantum charge-coupled device (QCCD) architecture, which the H-Series is built on, the hardware team at Quantinuum introduced a series of component innovations, to eliminate some performance limitations of the first generation in areas such as ion-loading, voltage sources, and delivering high-precision radio signals to control and manipulate ions.
The research paper, “A Race Track Trapped-Ion Quantum Processor,” details all of these engineering advances, and exactly what impacts they have on the computing performance of the machine. The paper includes results from component and system-level benchmarking tests that document the new machine’s capabilities at launch. These benchmarking metrics, combined with the company’s advances in topological qubits, represent a new phase of quantum computing.
Advancing Beyond Classical Simulation
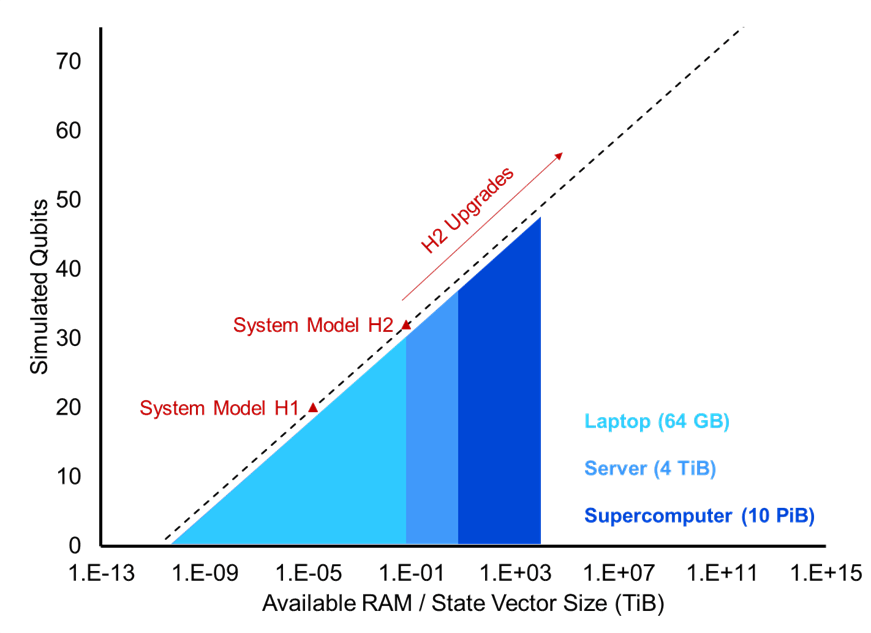
In addition to the expanded capabilities, the new design provides operational efficiencies and a clear growth path.
At launch, H2’s operations can still be emulated classically. However, Quantinuum released H2 at a small percentage of its full capacity. This new machine has the ability to upgrade to more qubits and gate zones, pushing it past the level where classical computers can hope to keep up.
Increased Efficiency in New Trap Design
This new generation quantum processor represents the first major trap upgrade in the H-Series. One of the most significant changes is the new oval (or racetrack) shape of the ion trap itself, which allows for a more efficient use of space and electrical control signals.
One key engineering challenge presented by this new design was the ability to route signals beneath the top metal layer of the trap. The hardware team addressed this by using radiofrequency (RF) tunnels. These tunnels allow inner and outer voltage electrodes to be implemented without being directly connected on the top surface of the trap, which is the key to making truly two-dimensional traps that will greatly increase the computational speed of these machines.
The new trap also features voltage “broadcasting,” which saves control signals by tying multiple DC electrodes within the trap to the same external signal. This is accomplished in “conveyor belt” regions on each side of the trap where ions are stored, improving electrode control efficiency by requiring only three voltage signals for 20 wells on each side of the trap.
The other significant component of H2 is the Magneto Optical Trap (MOT) which replaces the effusive atomic oven that H1 used. The MOT reduces the startup time for H2 by cooling the neutral atoms before shooting them at the trap, which will be crucial for very large machines that use large numbers of qubits.
Industry-leading Results from 15 Benchmarking Tests
Quantinuum has always valued transparency and supported its performance claims with publicly available data.
To quantify the impact of these hardware and design improvements, Quantinuum ran 15 tests that measured component operations, overall system performance and application performance. The complete results from the tests are included in the new research paper.
The hardware team ran four system-level benchmark tests that included more complex, multi-qubit circuits to give a broader picture of overall performance. These tests were:
- Mirror benchmarking: A scalable way to benchmark arbitrary quantum circuits.
- Quantum volume: A popular system-level test with a well-established construction that is comparable across gate-based quantum computers.
- Random circuit sampling: A computational task of sampling the output distributions of random quantum circuits.
- Entanglement certification in Greenberger-Horne-Zeilinger (GHZ) states: A demanding test of qubit coherence that is widely measured and reported across a variety of quantum hardware.
H2 showed state-of-the-art performance on each of these system-level tests, but the results of the GHZ test were particularly impressive. The verification of the globally entangled GHZ state requires a relatively high fidelity, which becomes harder and harder to achieve with larger numbers of qubits.
With H2’s 32 qubits and precision control of the environment in the ion trap, Quantinuum researchers were able to achieve an entangled state of 32 qubits with a fidelity of 82.0(7)%, setting a new world record.
In addition to the system level tests, the Quantinuum hardware team ran these component benchmark tests:
- SPAM experiment
- Single-qubit gate randomized benchmarking
- Two-qubit gate randomized benchmarking
- Two-qubit SU gate randomized benchmarking RB
- Two-qubit parameterized gate randomized benchmarking
- Measurement/reset crosstalk benchmarking
- Interleaved transport randomized benchmarking
The paper includes results from those tests as well as results from these application benchmarks:
- Hamiltonian simulation
- Quantum Approximate Optimization Algorithm
- Error correction: repetition code
- Holographic quantum dynamics simulation
About Quantinuum
Quantinuum, the world’s largest integrated quantum company, pioneers powerful quantum computers and advanced software solutions. Quantinuum’s technology drives breakthroughs in materials discovery, cybersecurity, and next-gen quantum AI. With over 500 employees, including 370+ scientists and engineers, Quantinuum leads the quantum computing revolution across continents.
It is believed that unlocking answers to some of the most complex scientific and industrial problems will require the seamless integration of high-performance computing (HPC), generative AI (GenAI), and quantum computing. Toward this goal, Quantinuum, NVIDIA, and a major pharmaceutical company have successfully demonstrated the first step in a proof-of-principle framework designed to connect these three distinct computing paradigms for industrially relevant computational chemistry.
This milestone, enabled by three industry leaders and experts in their respective domains, serves as a foundational capability that could support the development of future hybrid quantum-AI workflows to help optimize industrial research and development (R&D).
The potential value is a path toward more automated, repeatable, and scalable workflows for translating chemistry problems into executable quantum programs—capabilities that could eventually make hybrid computing easier to deploy in industrial R&D.
The GenQAI Framework
The framework, termed Generative Quantum AI (GenQAI), involved a quantum computer simulating a pharmaceutical compound using programming instructions generated by an AI model, which itself was trained on quantum data that was simulated using HPC.
While the vision for GenQAI explores how future industrial simulation workflows might be optimized by training AI models using quantum data derived directly from a quantum computer, the framework currently consists of four main technical steps:
- Simulating quantum data: The process began by simulating quantum data with NVIDIA accelerated computing using NVIDIA CUDA-Q.
- Fine-tuning the AI: This simulated quantum data was used to fine-tune a pre-trained AI model from the open NVIDIA Nemotron family.
- Generating instructions: The AI model then generated quantum circuits, which are the programming instructions required for the quantum simulation.
- Validating accuracy: To validate the results, the circuits were run on Quantinuum’s Helios quantum computer using its InQuanto quantum chemistry platform.
The core novelty of this development lies within the process of the framework itself. In this proof-of-principle experiment, an AI model fine-tuned on simulated quantum data generated circuits that were successfully executed and validated on Quantinuum’s Helios system. Rather than delivering an immediate commercial advantage, this achievement establishes a credible, verifiable baseline for how HPC, AI, and quantum computing can function in tandem.
The Case Study
The validation of the framework represents an early step toward the goal of developing scalable architectures for the pharmaceutical industry.
With a shared view toward eventually scaling the framework for pharmaceutical R&D applications, the researchers simulated a pharmaceutical compound: imipramine. This anti-depressant was chosen because it serves as a model compound for drug degradation and shelf-life studies, which are standard components of the pharmaceutical R&D lifecycle.
Developing hybrid infrastructure that enterprises may adopt requires a deep, coordinated effort among domain experts. As such, this successful test highlights the value of combining the strengths of a quantum computing hardware and software leader (Quantinuum), with a hybrid-quantum classical platform (NVIDIA), and a leading enterprise end-user to build and test future computing capabilities for industrial chemistry.
Scaling the Framework
Although demonstrated on a pharmaceutical compound, the architecture could eventually inform similar molecular-simulation workflows in sectors such as energy, agriculture, advanced materials, and electronics. At this stage, it provides a reference for further testing and development.
Engage Further
Access the paper here to explore the full technical details of this demonstration and contact our team to learn more about joining Quantinuum’s enterprise partner network.

Quantinuum is pleased to announce that applications are now open for the Quantinuum SG Grand Challenge 2026, a global innovation challenge designed to bring together researchers, developers, scientists and innovators to explore practical applications of quantum computing.
Organized by Quantinuum and supported by Singapore's National Quantum Office and Aqora, the three-month program aims to foster collaboration across academia, industry and the quantum developer community while supporting the continued growth of Singapore's quantum ecosystem.
A Platform for Quantum Computing Innovation
Participants will work in teams to develop solutions across a range of challenge areas, including chemistry and molecular simulation, optimization, AI for quantum systems, quantum error correction, condensed matter and materials science, and open innovation. Throughout the program, participants will have access to mentoring, technical enablement and Quantinuum quantum computing resources.
Singapore Grand Finale
Selected finalist teams will be invited to present their work at the Grand Finale hosted in Singapore before representatives from academia, and industry. The event will celebrate innovative applications of quantum computing while providing an opportunity for participants to engage with Singapore's growing quantum community.
Join the Challenge
The Quantinuum SG Grand Challenge welcomes participants from around the world. Whether you are an experienced quantum researcher or beginning your quantum computing journey, the program offers an opportunity to collaborate, learn and contribute to the development of practical quantum applications.
Applications are now open. Spaces are limited and subject to review and approval.
- Researchers from Quantinuum, Caltech, the University of Chicago, and Harvard created a rare topologically ordered state of matter on Quantinuum's System Model H2 and used it to perform protected universal quantum gates with non-Abelian anyons.
- The work explores an alternative approach to fault tolerance by using topological properties to protect quantum information. This could reduce the need for magic state distillation, which can (in some circumstances) be resource-intensive.
- Quantinuum continues to show leadership in fault tolerance, with successful demonstrations spanning world record error rates to exotic approaches like topological computing
Quantum computing is all about putting the exotic properties of physics to work. Qubits can exist in two states at once, like the famous cat that is both alive and dead. Qubits can also be entangled, where the state of one will instantaneously affect the state of another - even when they have no way to “talk” to each other. Qubits can even be teleported, moving a quantum state from one place to another without physically moving it through space.
These features give quantum computing its power. But the ‘spooky’ nature of quantum computing doesn’t stop there: our quantum computers are potent enough to make exotic states of matter out of our qubits, and to perform calculations that would warp the mind of more traditional thinkers.
A new approach
In a recent paper published in Nature, researchers at Quantinuum teamed up with Caltech, the University of Chicago, and Harvard to create a rare ‘topologically ordered’ state of matter from our qubits.
When the qubits become ‘topologically ordered’, they become more than individual particles, now ‘related’ to each other in a specific way. This is like how hydrogen and oxygen act as individual gas particles alone, but you can put them together in a certain way so that they become water, a liquid, and an entirely different creature.
When the qubits become topologically ordered, the quantum information that they carried individually gets spread out over the whole system, which acts as a sort of protection from noise. This is like how a net makes a stronger barrier than a bunch of un-knotted ropes.
Once the researchers had topologically ordered qubits, they used the exotic particles that resulted (called non-Abelian anyons) to compute, performing error-protected gates and measurements.
To perform gates, the researchers 'braided' the anyons, which is like changing the shape of the “net”. This is something like the children’s game ‘cats cradle’. Through a sequence of changes to the “net”, the quantum computer can perform full calculations, one day helping scientists to understand the secrets hidden in the world around us.
Why go to such trouble? Well, for the love of discovery of course - but the team had an additional, specific motivation. One of the biggest challenges in building practical quantum computers is protecting them from errors while still being able to perform every operation needed for computation (this is referred to as universality).
This work takes a fresh approach to this challenge. Unlike traditional quantum error correction, the special properties of topological matter enable a universal set of fault tolerant gates without relying on expensive magic state distillation.
Why this matters
Quantum error correction is essential for large-scale quantum computing. While it protects fragile quantum information from noise by turning delicate physical qubits into robust logical qubits, it also introduces a significant constraint: not every quantum gate can be performed directly on logical qubits.
For decades, the standard solution has been to supplement error-corrected operations with magic states. These specially prepared quantum resources enable universal computation but can come at a steep cost - in many estimates of future fault-tolerant quantum computers, magic state preparation dominates both the physical qubit count and the runtime of useful algorithms.
Reducing this overhead has therefore become an important goal in quantum computing. This new approach may significantly reduce the cost by enabling the ‘topological preparation’ of magic states, eliding expensive protocols like distillation. If universal computation can be performed without large-scale magic state distillation, quantum computers could require significantly fewer physical qubits and spend much less time generating computational resources before running useful algorithms.
We will never stop exploring
While there is still considerable work ahead to understand the practical implementation and scalability of these ideas, this result expands the landscape of what's possible in quantum fault tolerance.
Of course, this impressive demonstration describes just one approach we are taking to fault tolerance at scale. We will continue to push forward with topological computing alongside more traditional approaches to quantum error correction, as well as exploring everything we can imagine in between. We are looking at a number of ways to reduce the resource cost of magic states in particular, and are making strides in multiple dimensions. With machines that are both flexible and accurate enough to do it all, who can resist?