

Untangling the Mysteries of Knots with Quantum Computers
What Quantum Advantage actually looks like
By Konstantinos Meichanetzidis
One of the greatest privileges of working directly with the world’s most powerful quantum computer at Quantinuum is building meaningful experiments that convert theory into practice. The privilege becomes even more compelling when considering that our current quantum processor – our H2 system – will soon be enhanced by Helios, a quantum computer potentially a stunning trillion times more powerful, and due for launch in just a few months. The moment has now arrived when we can build a timeline for applications that quantum computing professionals have anticipated for decades and which are experimentally supported.
Quantinuum’s applied algorithms team has released an end-to-end implementation of a quantum algorithm to solve a central problem in knot theory. Along with an efficiently verifiable benchmark for quantum processors, it allows for concrete resource estimates for quantum advantage in the near-term. The research team, included Quantinuum researchers Enrico Rinaldi, Chris Self, Eli Chertkov, Matthew DeCross, David Hayes, Brian Neyenhuis, Marcello Benedetti, and Tuomas Laakkonen of the Massachusetts Institute of Technology. In this article, Konstantinos Meichanetzidis, a team leader from Quantinuum’s AI group who led the project, writes about the problem being addressed and how the team, adopting an aggressively practical mindset, quantified the resources required for quantum advantage:
Knot theory is a field of mathematics called ‘low-dimensional topology’, with a rich history, stemming from a wild idea proposed by Lord Kelvin, who conjectured that chemical elements are different knots formed by vortices in the aether. Of course, we know today that the aether theory was falsified by the Michelson-Morley experiment, but mathematicians have been classifying, tabulating, and studying knots ever since. Regarding applications, the pure mathematics of knots can find their way into cryptography, but knot theory is also intrinsically related to many aspects of the natural sciences. For example, it naturally shows up in certain spin models in statistical mechanics, when one studies thermodynamic quantities, and the magnetohydrodynamical properties of knotted magnetic fields on the surface of the sun are an important indicator of solar activity, to name a few examples. Remarkably, physical properties of knots are important in understanding the stability of macromolecular structures. This is highlighted by work of Cozzarelli and Sumners in the 1980’s, on the topology of DNA, particularly how it forms knots and supercoils. Their interdisciplinary research helped explain how enzymes untangle and manage DNA topology, crucial for replication and transcription, laying the foundation for using mathematical models to predict and manipulate DNA behavior, with broad implications in drug development and synthetic biology. Serendipitously, this work was carried out during the same decade as Richard Feynman, David Deutsch, and Yuri Manin formed the first ideas for a quantum computer.
Most importantly for our context, knot theory has fundamental connections to quantum computation, originally outlined by Witten’s work in topological quantum field theory, concerning spacetimes without any notion of distance but only shape. In fact, this connection formed the very motivation for attempting to build topological quantum computers, where anyons – exotic quasiparticles that live in two-dimensional materials – are braided to perform quantum gates. The relation between knot theory and quantum physics is the most beautiful and bizarre facts you have never heard of.
The fundamental problem in knot theory is distinguishing knots, or more generally, links. To this end, mathematicians have defined link invariants, which serve as ‘fingerprints’ of a link. As there are many equivalent representations of the same link, an invariant, by definition, is the same for all of them. If the invariant is different for two links then they are not equivalent. The specific invariant our team focused on is the Jones polynomial.

They all have the same Jones polynomial, as it is an invariant.

The mind-blowing fact here is that any quantum computation corresponds to evaluating the Jones polynomial of some link, as shown by the works of Freedman, Larsen, Kitaev, Wang, Shor, Arad, and Aharonov. It reveals that this abstract mathematical problem is truly quantum native. In particular, the problem our team tackled was estimating the value of the Jones polynomial at the 5th root of unity. This is a well-studied case due to its relation to the infamous Fibonacci anyons, whose braiding is capable of universal quantum computation.
Building and improving on the work of Shor, Aharonov, Landau, Jones, and Kauffman, our team developed an efficient quantum algorithm that works end-to end. That is, given a link, it outputs a highly optimized quantum circuit that is readily executable on our processors and estimates the desired quantity. Furthermore, our team designed problem-tailored error detection and error mitigation strategies to achieve a higher accuracy.
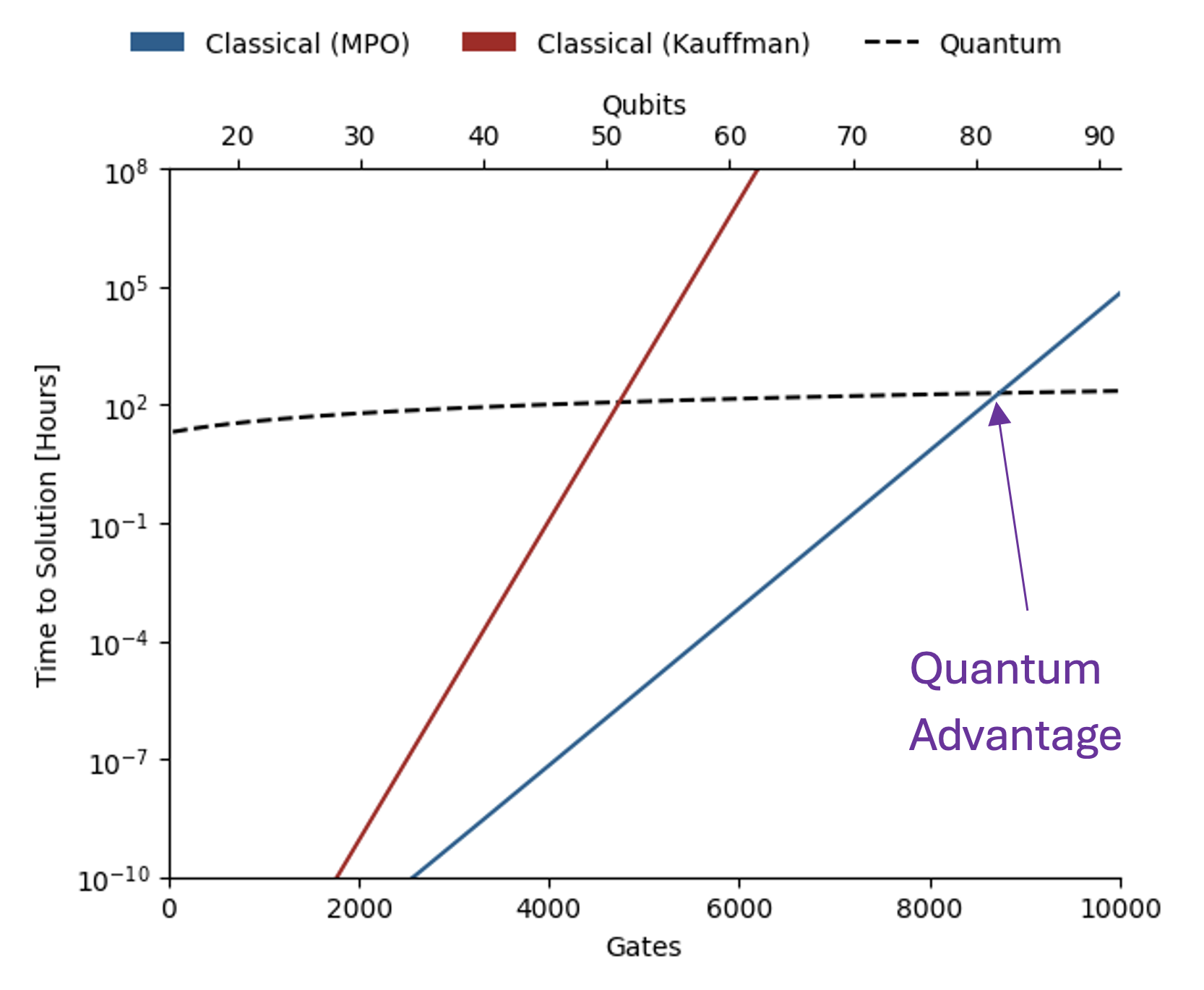
In addition to providing a full pipeline for solving this problem, a major aspect of this work was to use the fact that the Jones polynomial is an invariant to introduce a benchmark for noisy quantum computers. Most importantly, this benchmark is efficiently verifiable, a rare property since for most applications, exponentially costly classical computations are necessary for verification. Given a link whose Jones polynomial is known, the benchmark constructs a large set of topologically equivalent links of varying sizes. In turn, these result in a set of circuits of varying numbers of qubits and gates, all of which should return the same answer. Thus, one can characterize the effect of noise present in a given quantum computer by quantifying the deviation of its output from the known result.
The benchmark introduced in this work allows one to identify the link sizes for which there is exponential quantum advantage in terms of time to solution against the state-of-the-art classical methods. These resource estimates indicate our next processor, Helios, with 96 qubits and at least 99.95% two-qubit gate-fidelity, is extremely close to meeting these requirements. Furthermore, Quantinuum’s hardware roadmap includes even more powerful machines that will come online by the end of the decade. Notably, an advantage in energy consumption emerges for even smaller link sizes. Meanwhile, our teams aim to continue reducing errors through improvements in both hardware and software, thereby moving deeper into quantum advantage territory.
The importance of this work, indeed the uniqueness of this work in the quantum computing sector, is its practical end-to-end approach. The advantage-hunting strategies introduced are transferable to other “quantum-easy classically-hard” problems. Our team’s efforts motivate shifting the focus toward specific problem instances rather than broad problem classes, promoting an engineering-oriented approach to identifying quantum advantage. This involves first carefully considering how quantum advantage should be defined and quantified, thereby setting a high standard for quantum advantage in scientific and mathematical domains. And thus, making sure we instill confidence in our customers and partners.
Edited
About Quantinuum
Quantinuum, the world’s largest integrated quantum company, pioneers powerful quantum computers and advanced software solutions. Quantinuum’s technology drives breakthroughs in materials discovery, cybersecurity, and next-gen quantum AI. With over 500 employees, including 370+ scientists and engineers, Quantinuum leads the quantum computing revolution across continents.
- Mitsui & Co. and Mitsubishi Electric demonstrated one of the world’s largest approximate Quantum Fourier Transforms (QFT) on Quantinuum Helios, scaling from prior records to 98 physical qubits.
- The collaboration also implemented a logical QFT using a QEC (Quantum Error Correction) code with up to 12 logical qubits.
- The work highlights Quantinuum’s accuracy and flexible architecture.
While there is ongoing debate around the pace of quantum computing’s development, a more grounded way to assess progress is through concrete demonstrations of foundational algorithms at meaningful scale. In this context, Mitsui & Co. and Mitsubishi Electric are taking a pragmatic view of quantum progress—focusing on how close the field is to executing core algorithmic primitives that underpin many potential industrial applications, rather than relying on abstract milestones or timelines.
In a new white paper, the industrial giants teamed up with Quantinuum to measure how close we are to running the Quantum Fourier Transform (QFT), a widely-used algorithmic primitive, at scales necessary for industrial applications. In the process, the team successfully ran one of the largest instances of the approximate QFT ever demonstrated. This achievement matters because the QFT is an essential primitive that underpins many of the quantum algorithms expected to deliver practical advantages.
You may have heard of the (classical) Fourier transform (FT), due to its ubiquity throughout modern computing. The FT is essential in everything from image analysis to data compression, with almost limitless applications in between. The quantum Fourier transform (QFT) is similar; it’s used in everything from chemistry to finance.
Because the QFT is a foundational primitive underpinning many quantum algorithms, demonstrating it at larger scales and higher fidelity is a practical way to measure quantum computing readiness. This is exactly the type of benchmarking that organizations should consider to understand where today’s systems are useful, and to see how fault-tolerant approaches are progressing. Ultimately, algorithm-level benchmarking like this is one of the most useful ways to understand not just where we are, but where we are going.
A Transformative Approach
Primitives like Fourier Transform are so widespread because they simplify problems by transforming them into something that is easier to deal with. At Quantinuum, we are very interested in transforms: not only are they crucial for industrial applications but they can also simplify algorithms, making them possible to run now instead of later. This ‘transformational’ approach extends beyond the QFT - other transforms exist, and we have even invented our own quantum-native transforms.
Using our Helios quantum computer and Guppy language, the joint team explored running the QFT on both physical qubits and on logical qubits, showing that fault tolerance is progressing quickly. Running the QFT on 98 physical qubits; the paper shows a clear progression from previous results.
Then, using the Steane code, one of the best-studied quantum error correcting codes, the team used Helios’ 98 physical qubits to form 12 logical qubits, successfully running the QFT with the mechanisms of quantum error correction interwoven into the algorithm. This marks a crucial step forward for the field.
Foundational Progress
Taken together, these results provide a more concrete lens through which to view progress in quantum computing: not as abstract projections, but as measurable advances in the execution of foundational algorithms at increasing scale. By benchmarking the Quantum Fourier Transform on both physical and logical qubits, Mitsui & Co. and Mitsubishi Electric are helping to clarify what today’s hardware can already achieve, and where fault-tolerant approaches begin to extend those limits.
More broadly, the organizations best positioned to benefit from quantum computing will be those that focus on these foundational capabilities early, and use them to build a clear, evidence-based understanding of how the technology fits into their business goals.
It is believed that unlocking answers to some of the most complex scientific and industrial problems will require the seamless integration of high-performance computing (HPC), generative AI (GenAI), and quantum computing. Toward this goal, Quantinuum, NVIDIA, and a major pharmaceutical company have successfully demonstrated the first step in a proof-of-principle framework designed to connect these three distinct computing paradigms for industrially relevant computational chemistry.
This milestone, enabled by three industry leaders and experts in their respective domains, serves as a foundational capability that could support the development of future hybrid quantum-AI workflows to help optimize industrial research and development (R&D).
The potential value is a path toward more automated, repeatable, and scalable workflows for translating chemistry problems into executable quantum programs—capabilities that could eventually make hybrid computing easier to deploy in industrial R&D.
The GenQAI Framework
The framework, termed Generative Quantum AI (GenQAI), involved a quantum computer simulating a pharmaceutical compound using programming instructions generated by an AI model, which itself was trained on quantum data that was simulated using HPC.
While the vision for GenQAI explores how future industrial simulation workflows might be optimized by training AI models using quantum data derived directly from a quantum computer, the framework currently consists of four main technical steps:
- Simulating quantum data: The process began by simulating quantum data with NVIDIA accelerated computing using NVIDIA CUDA-Q.
- Fine-tuning the AI: This simulated quantum data was used to fine-tune a pre-trained AI model from the open NVIDIA Nemotron family.
- Generating instructions: The AI model then generated quantum circuits, which are the programming instructions required for the quantum simulation.
- Validating accuracy: To validate the results, the circuits were run on Quantinuum’s Helios quantum computer using its InQuanto quantum chemistry platform.
The core novelty of this development lies within the process of the framework itself. In this proof-of-principle experiment, an AI model fine-tuned on simulated quantum data generated circuits that were successfully executed and validated on Quantinuum’s Helios system. Rather than delivering an immediate commercial advantage, this achievement establishes a credible, verifiable baseline for how HPC, AI, and quantum computing can function in tandem.
The Case Study
The validation of the framework represents an early step toward the goal of developing scalable architectures for the pharmaceutical industry.
With a shared view toward eventually scaling the framework for pharmaceutical R&D applications, the researchers simulated a pharmaceutical compound: imipramine. This anti-depressant was chosen because it serves as a model compound for drug degradation and shelf-life studies, which are standard components of the pharmaceutical R&D lifecycle.
Developing hybrid infrastructure that enterprises may adopt requires a deep, coordinated effort among domain experts. As such, this successful test highlights the value of combining the strengths of a quantum computing hardware and software leader (Quantinuum), with a hybrid-quantum classical platform (NVIDIA), and a leading enterprise end-user to build and test future computing capabilities for industrial chemistry.
Scaling the Framework
Although demonstrated on a pharmaceutical compound, the architecture could eventually inform similar molecular-simulation workflows in sectors such as energy, agriculture, advanced materials, and electronics. At this stage, it provides a reference for further testing and development.
Engage Further
Access the paper here to explore the full technical details of this demonstration and contact our team to learn more about joining Quantinuum’s enterprise partner network.

Quantinuum is pleased to announce that applications are now open for the Quantinuum SG Grand Challenge 2026, a global innovation challenge designed to bring together researchers, developers, scientists and innovators to explore practical applications of quantum computing.
Organized by Quantinuum and supported by Singapore's National Quantum Office and Aqora, the three-month program aims to foster collaboration across academia, industry and the quantum developer community while supporting the continued growth of Singapore's quantum ecosystem.
A Platform for Quantum Computing Innovation
Participants will work in teams to develop solutions across a range of challenge areas, including chemistry and molecular simulation, optimization, AI for quantum systems, quantum error correction, condensed matter and materials science, and open innovation. Throughout the program, participants will have access to mentoring, technical enablement and Quantinuum quantum computing resources.
Singapore Grand Finale
Selected finalist teams will be invited to present their work at the Grand Finale hosted in Singapore before representatives from academia, and industry. The event will celebrate innovative applications of quantum computing while providing an opportunity for participants to engage with Singapore's growing quantum community.
Join the Challenge
The Quantinuum SG Grand Challenge welcomes participants from around the world. Whether you are an experienced quantum researcher or beginning your quantum computing journey, the program offers an opportunity to collaborate, learn and contribute to the development of practical quantum applications.
Applications are now open. Spaces are limited and subject to review and approval.